
When dealing with large repositories, especially those that are containing lots of libraries, applications and many developers working concurrently on a code base, you will experience performance challenges in your CI/CD pipeline that we are trying to address here.
Hands-on knowledge of one or more tools of the following is required to fully understand this blog post: git, Nx Workspace, Jenkins, jest or vitest
One of the main performance issues in Nx Workspace mono-repositories is the test and build time. The pipeline execution time can become longer due to a large number of projects and dependencies, as well as the way Nx manages them. This can lead to a slow feedback loop, which can be frustrating for developers who need to wait for the build to complete before they can test their changes.
On a big customer project, we experienced constantly growing pipeline runtimes since more and more teams got onboarded and we had to do something about it. Some of the improvements we have taken can be found in this article.
TLDR; The bottlenecks at a glance
- git clone
- checkout by default downloads all history and file blobs. Use
git clone --filter=blob:none --no-tagsto have a low footprint while still having all history on hand. Best to be used for local development, when shallow clone (git clone --depth=1) is not applicable.
- checkout by default downloads all history and file blobs. Use
- nx:affected
- slow on a complex component/app graph in subsequent usage. Write the
nx:affectedoutput to a file and reuse it in subsequent stages without any computation.
- slow on a complex component/app graph in subsequent usage. Write the
- jest / vitest
- tests can be multithreaded and parallelized. Based on underlying CPU threads available in your executing environment, set parallel options
nx --parallel --maxParallel=Nto the according number and to further speed up, use Jenkinsparalleltogether with sharding, eg--shard=1/3and let parts of the test suites be executed in parallel. Lower memory footprint, faster execution without manually splitting of test suites.
- tests can be multithreaded and parallelized. Based on underlying CPU threads available in your executing environment, set parallel options
Checkout improvement - git clone options
Let’s start with a quick overview of git clone options to speed up our development and pipeline checkout.
By default, git clone retrieves the whole history with all changes and files that have ever been committed since repository creation. The following arguments can help reduce checkout time and size:
git clone --filter=blob:none --no-tagsfetches the full history and loads trees and file-blobs on-demand. This one is recommended for development as well as pipeline checkouts that span multiple builds and require history and trees. In our case, it saves around 90% disk space.git clone --tree=0similar to blob:none filter, it loads trees and file blobs on demand.git clone --depth=1 <url>creates a shallow clone, which is a huge space saver and probably the most used for pipelines. It is used for one-time runs that do not require access to git history or other trees.
Nx Workspace - improving nx:affected
One of the main performance issues in Nx Workspace mono-repositories is the build time. The build time can become longer due to a large number of projects and dependencies, as well as the way Nx manages them. This can lead to a slow feedback loop, which can be frustrating for developers who need to wait for the build to complete before they can test their changes.
Another performance issue is related to the test time. A large number of projects and dependencies can cause the test time to increase significantly, which can slow down the development process. Additionally, the tests themselves can become more complex and time-consuming, especially in large-scale applications.
To address these performance issues, there are several strategies that can be implemented. One approach is to use parallelization to speed up the build and test time. This can involve running multiple jobs simultaneously, which can help to reduce the overall time required to complete the build and test process.
Let’s take a look at the nx:affected --target=XY command first. This is fine when running against just a few targets, but if you are using custom schematics and have many tasks that need to be run on a set of projects, you might see significantly longer pipeline runs. In our case getting the affected apps and libraries took around 50 seconds, which added 10 minutes to the pipeline, given a number of around 10 targets (like lint and build).
One easy way is to compute once and store the outcome as a variable for reuse in the pipeline steps. We are doing this with the following script:
/**
* Retrieves the affected angular projects in json format
*
* Can be used within shell scripts to return a stringified result
* And exports a method when imported in node scripts
*
* Environment vars:
* JSON: filename to output, if not provided, a method is exported to be used in node scripts
* BASE_TARGET: override comparison target, using the given hash or target (eg: origin/main)
*
*
* JSON=affected-projects.json node get-affected.js
* JSON=affected-projects.json BASE_TARGET=origin/main node get-affected-libs.js
* or
* const affected = require('./get-affected');
*
* @returns array of objects: [{project, projectType, root, sourceRoot}]
*/
const storeFile = process.env.JSON || false;
const baseTarget = process.env.BASE_TARGET || 'HEAD';
const fs = require('fs');
const { execSync } = require('child_process');
const repoRoot = __dirname + '/';
const { projects } = require('./angular.json')
const mapAngularProjects = (projectKey) => {
const project = projects[projectKey];
if (!project) {
return null;
}
return {
project: projectKey,
projectType: project.projectType,
root: project.root,
sourceRoot: project.sourceRoot
}
}
const getAffected = async () => {
const affectedPlain =
execSync(
repoRoot + 'node_modules/.bin/nx affected:libs --silent --base=' + baseTarget + ' --plain'
).toString();
const affectedJson = affectedPlain
.split(' ')
.map((a) => a.trim())
.filter((a) => !!a);
// map to angular.json projects
return affectedJson
.map(mapAngularProjects)
.filter((p) => !!p);
};
if (storeFile) {
getAffected().then((res) =>
fs.writeFileSync(repoRoot + storeFile, JSON.stringify(res, null, 2))
);
} else {
module.exports = getAffected;
}
get-affected.js
The following snippet shows how to use it in Jenkins. It runs the script, which outputs to a file. This file is being read and stored in a variable. Since we need only the project names for the run-many command, the names are enough to store. Other tasks like publish or build steps might need other values from the generated file.
def projects
def projectNames
def hasAffectedProjects
pipeline {
stage("Prepare") {
steps {
script {
sh "JSON=affected-projects.json node get-affected.js"
projects = readJSON(file: 'affected-projects.json')
projectNames = projects.collect { it.get('project') }
hasAffectedProjects = projects.size() > 0
}
}
}
stage("Test") {
when {
expression { return hasAffectedProjects }
}
steps {
script {
sh "yarn nx run-many --target=test --projects=${projectNames.join(',')} --parallel --maxParallel=4 --ci"
}
}
}
}
Jenkinsfile
Nx Workspace - parallelize tests and other schematics
To build, lint or test many projects in parallel, Nx ships its awesome nx run-many command, which is, in combination with --parallel perfectly suited to get the maximum performance out of the underlying build system. You can run nx run-many --target="build" --parallel --maxParallel=N while N should be the maximum number of cores/threads available in the build pod (eg if you build on Jenkins workers). This suits for most of the use cases but if you experience issues with your tests running in parallel, read the next chapter.
One issue with testing in our jest tests is flakiness, while we were investigating on that (jest open handles and other issues), we found that jest’s --runInBand in combination with Nx’s --parallel was leading to frequent pipeline fails. We had to transitional use the slow option instead and run without --parallel.
Jenkins - parallelize jest / vitest
Whether or not you are running your tests with --parallel, or like we had to with --runInBand, you can further improve the overall speed of test execution by parallelizing in Jenkins itself.
Modern testing frameworks like jest and vitest provide a functionality named sharding, which allows one to select and run only a specific subset of tests based on a given fraction.
For jest, this could look like that for the first third of the tests: yarn nx run-many --target=test --all --ci --shard=1/3
Vitest provides an equal shard argument in its cli: vitest --run —-shard=1/3 In these cases, all test files found in all projects are collected and split up into three parts, evenly split up independent of test file size.
Now that we know how to split up tests, how do we run them in parallel on our Jenkins workers? Let’s reuse the Jenkins pipeline from above and update it accordingly. A definition for maxParallelShards was added and the Tests stage was replaced.
def projects
def projectNames
def hasAffectedProjects
def maxParallelShards = 3
pipeline {
stage("Prepare") {
steps {
script {
sh "JSON=affected-projects.json node get-affected.js"
projects = readJSON(file: 'affected-projects.json')
projectNames = projects.collect { it.get('project') }
hasAffectedProjects = projects.size() > 0
}
}
}
stage("Test") {
when {
expression { return hasAffectedProjects }
}
steps {
script {
sh "yarn nx run-many --target=test --projects=${projectNames.join(',')} --parallel --maxParallel=4 --ci"
}
}
}
stage("Tests") {
steps {
script {
def tests = [:]
for (int i = 1; i <= maxParallelShards; i++) {
tests["shard_${i}"] = {
node {
stage("Shard #${i}") {
sh "yarn nx run-many --target=test --projects=${projectNames.join(',')} --parallel --maxParallel=4 --ci --shard=${i}/${maxParallelShards}\""
}
}
}
}
parallel tests
}
}
}
}
Jenkinsfile
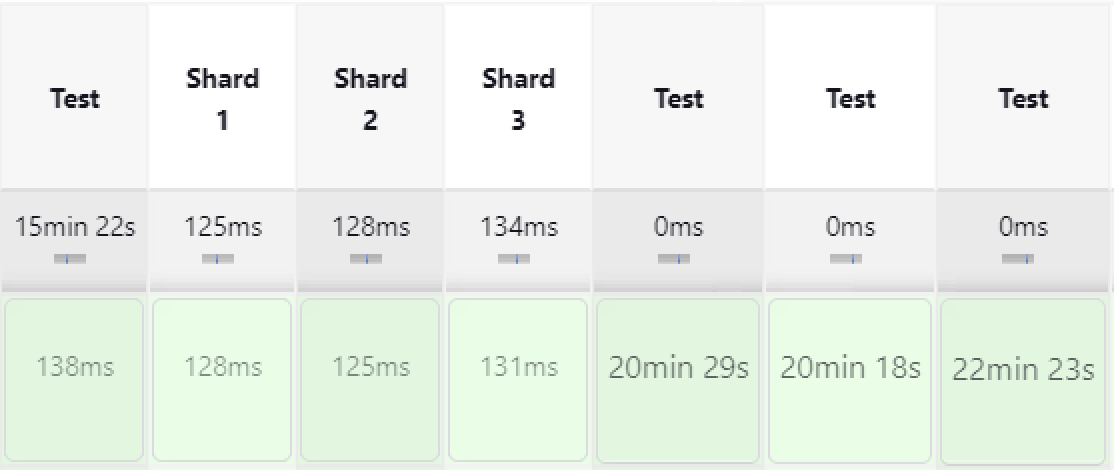
The for loop creates stages dynamically as an array, those get passed to the parallel Jenkins function. A Jenkins run with this setting shows the following output, the three Test stages were executed in parallel. Without parallelization you would only see the one Test stage that runs all Tests, cumulating the numbers you see here.
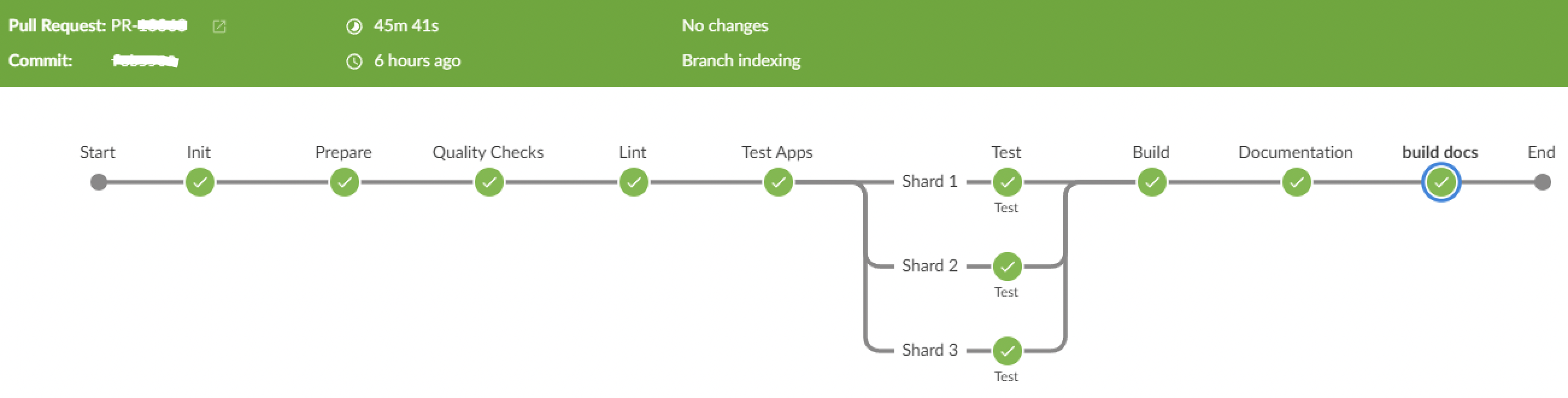
This is how it looks in Jenkins Blue Ocean, which expresses it a bit better visibly.
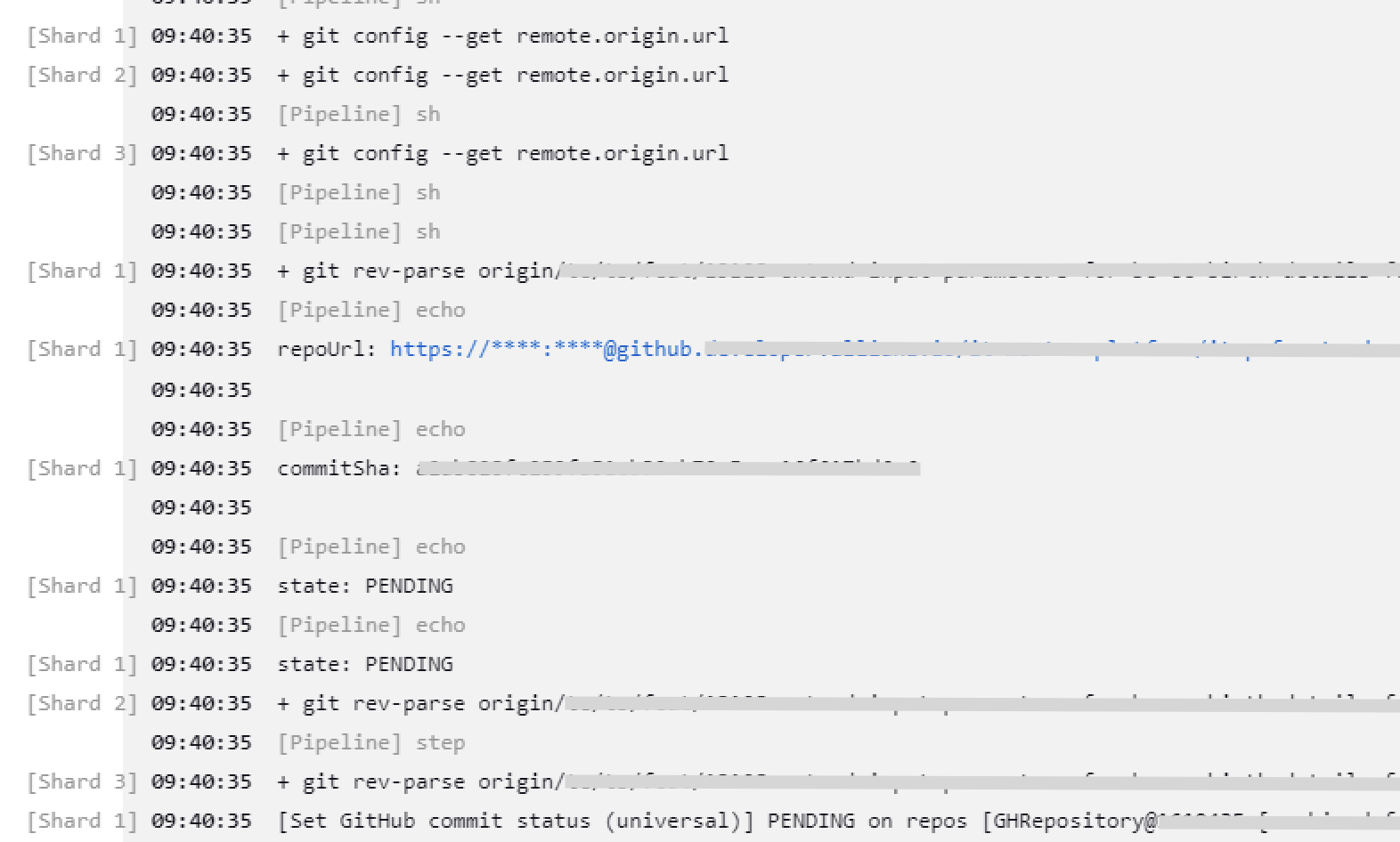
In the Jenkins complete log file, you see the stages prefixed by the stage name like in the screenshot below, to distinguish the shard in which a log entry appeared. Of course, you still have the possibility to inspect the logs of a specific stage to not get distracted by other shards’ logs.
Parallelization of stages is not limited to tests, but this is the lowest-hanging fruit.
We have further optimized by splitting up our projectNames to an array of project names (one for each allowed parallel stage) and are now able to also build, lint and run other targets in parallel by using nx run-many --target=build --projects={$projectNamesShards[index].join(',')} .
Comparison of our pipeline
Here are some numbers on how our pipeline runs improved given the pipeline you see in this picture:
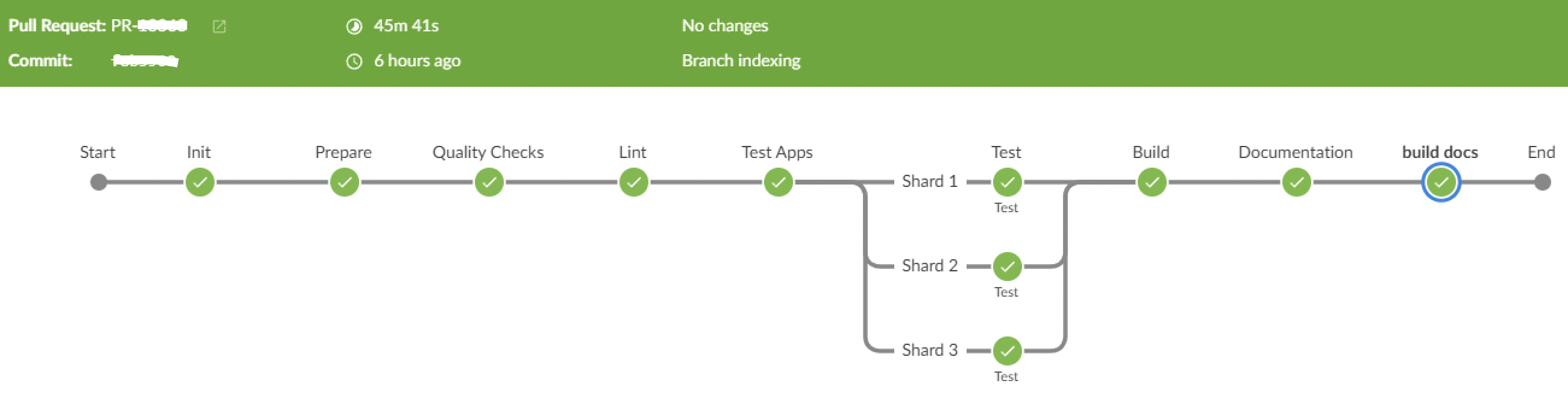
Initially, our pipeline ran for around 2 hours. Then we took those actions similar to those described in this article.
git clone —filter=blob:noneNot applicable in the pipeline, locally it saves around 500MB download for developers on potentially low bandwidthnx:affectedstored as JSON Prepare step runs for 2 minutes for package installation and initially affected computation, which takes around 1 minute. We have 7 to 8 targets running across the pipeline, each saving 1 minute since we run now withnx run-many --projectsinstead of affected. Runtime before: 9 min (nx:affectedin every stage) Runtime after: 2 min- Jenkins parallel stages with jest shards Saving is (total run time / N shards) + some overhead. Calculated on a full run with all projects affected. We are using 3 shards. Runtime before: 70 min Runtime after: 25 min
- Nx build time improvement Since the same projects that get tested are also being built, we can move the build target also into parallel steps. Runtime before: 15 min Runtime after: 5 min
Total time savings are around 50 minutes. So after optimization, our longest pipeline run is around 1h, so we cut down by half 💪
Conclusion
Optimizing your development workflow can greatly increase your productivity and efficiency. By understanding the bottlenecks that may slow down your process, you can take steps to minimize their impact. From using a slim git checkout to reusing nx:affectedoutput and parallelizing tests Jenkins stages, there are various techniques you can employ to speed up your pipeline processes. Implementing these improvements can greatly increase developer experience when working on Pull Requests.