
When using Large Language Models (LLM) there is a single big and important key factor: Context Size. That’s the total amount of content you can present the LLM and it dictates the amount of information an LLM can consider when generating responses.Depending on your use case the context size can be quite a limiting factor. There is a smart workaround: RAG. In this post I will explain a few things about context size and how RAG solves its limitations. Reading this post requires only a little knowledge about LLMs in general.
The Context Window
The context window size of prominent LLM models these days hovers between 192 to 300 pages of text. I’ve included 5 models as an example in the chart below.

That amount of context covers a lot of scenarios, especially when you’re only asking general question and you assume the LLM has an answer. Anytime you have a follow-up question the content in your context window grows as the LLM usually maintains your chat history, which includes your questions and previous answers. Still, the available context window sizes of LLMs should be just be fine for most people.

Sometimes you want to include additional information that the LLM can’t know. Like some very recent facts not present when training happened, a text you wrote yourself or some code you want to examine. Nothing a typical context window can’t handle these days when they can hold anything between 192 and 300 pages of text.

The moment you think about providing entire knowledge bases or a document management, like Atlassian’s Confluence, Microsoft SharePoint or your product database you have a problem: you probably have more than you can squeeze into the context window.

RAG
That’s when Retrieval-Augmented Generation, in short RAG, comes into play. It’s the bridge between your limited context window and your vast repository of knowledge.
The technique in a nutshell: As the context window size is limited, you don’t try to include all of your knowledge into it.
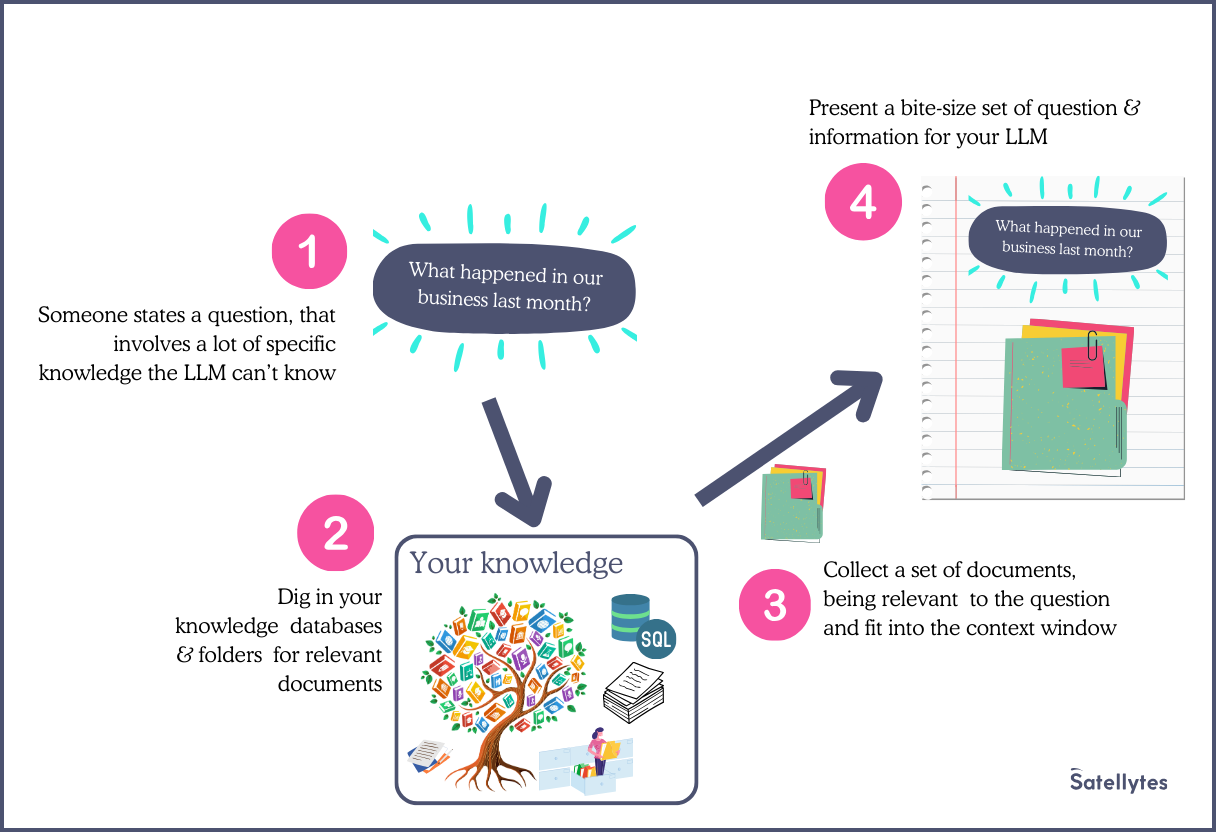
(1) Instead you begin with your raw question. (2) With that, you go to your knowledge database and retrieve what’s relevant to the given questions. (3) This yields a package of relevant documents or excerpts of them. (4) Which you nicely fits into the context window together with the original question.
While many people relate RAG exclusively to a vector database that’s not a requirement. You can use whatever works to retrieve relevant documents. In practice, often a keyword-based approach is used, usually being BM25 - an algorithm used by any traditional search engine like Google or Bing. You can even combine both approaches to build a hybrid RAG, where the semantic part finds a set of documents and you rerank them based on a second keyword based list of results.
Very Large Context Window Sizes
The context window sizes are growing larger and larger. While GPT-1 (2018) had a context size of 512 tokens, GPT-2 had 1024 tokens, GPT-3 2048 tokens and so on. Right now Gemini Pro 1.5/2.0 are reaching 2 Mio tokens and a paper of Google (”Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context”) suggest they have already tested up to 10 million tokens without degrading performance. That’s 15.000 pages of text.

This leads some people to the provoking idea that RAG might be obsolete given such a big context window size that can hold quite some big knowledge bases. The idea is simple, just squeeze everything you know into the prompt (that approach is even called “prompt stuffing”)
Even if you could squeeze your entire knowledge into a context window, it would be very inefficient to encode everything into tokens, wasting precious computation time, it would be surely more expensive, slower and in the end maybe even less accurate compared to any RAG approach.
Multimodal Tasks
The case for larger context window sizes is different. While you can transform a page of text into 375 tokens you need vastly more tokens for a multimodal content like video or audio.
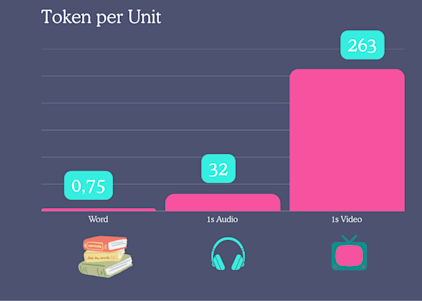
Let’s assume you speak 150 words per minute, then you would need for a page more than 3 minutes. While that page of text costs you only 375 tokens, you probably need a tenfold of tokens for audio (5760 tokens) and a hundredfold for video (25248 tokens).The motivation behind bigger context sizes mostly serves the multimodal experience of modern LLMs.
Conclusion
Context window sizes have been a limiting factor of LLMs in the past and yielded the RAG methodology. With sizes beyond 1M the context window size is not the limiting factor for text documents anymore but it doesn’t mean that RAG is obsolete. RAG still offers a practical and scalable solution for leveraging vast amounts of information by intelligently retrieving only the relevant context for a given query. Actually RAG feels more like a fundamental approach that has to be paired with LLM when prompting for knowledge.
When speaking of multimodal content, we can still see the context size as a limiting factor, as a movie of 120mins still consumes something close to 2M tokens so we’re far from throwing a set of videos onto a LLM to ask questions about it (ignoring the computional effort of doing that).
Lastly, Google has very recently released a Recall feature for their Gemini Advanced Chat, that allows it to include knowledge from previous chats in newly asked questions. Although they haven’t disclosed the underlying mechanism, which could be either a massive context window or a RAG infrastructure, this already demonstrates the kind of innovation enabled by larger context sizes.